
From Gorillas to AI: Missing the Unexpected
Reflections on my experience with vibe-coding, what we may gain and what we may miss

One month after Andrej Karpathy coined the term vibe coding in February 20251, I vibe-coded my website and wrote about the experience here.
I’m happy to report that the site is still live and well, and I got back into it when the time came to launch a new section to promote my speaking services. I did not expect the process of building the new speaker page with AI to be worthy of an essay (I’ve moved onto building scripts that run some tasks for me by now), but something so unexpected happened that I had to share.
Because I don’t know much about writing code, I started, as usual, asking Claude for the best possible prompt to achieve my goal: To build a new section of my site based on the text and pictures I had in a PDF with my speaker profile, making sure the new page was optimized for discovery through AI-powered search2.
And so I said it:
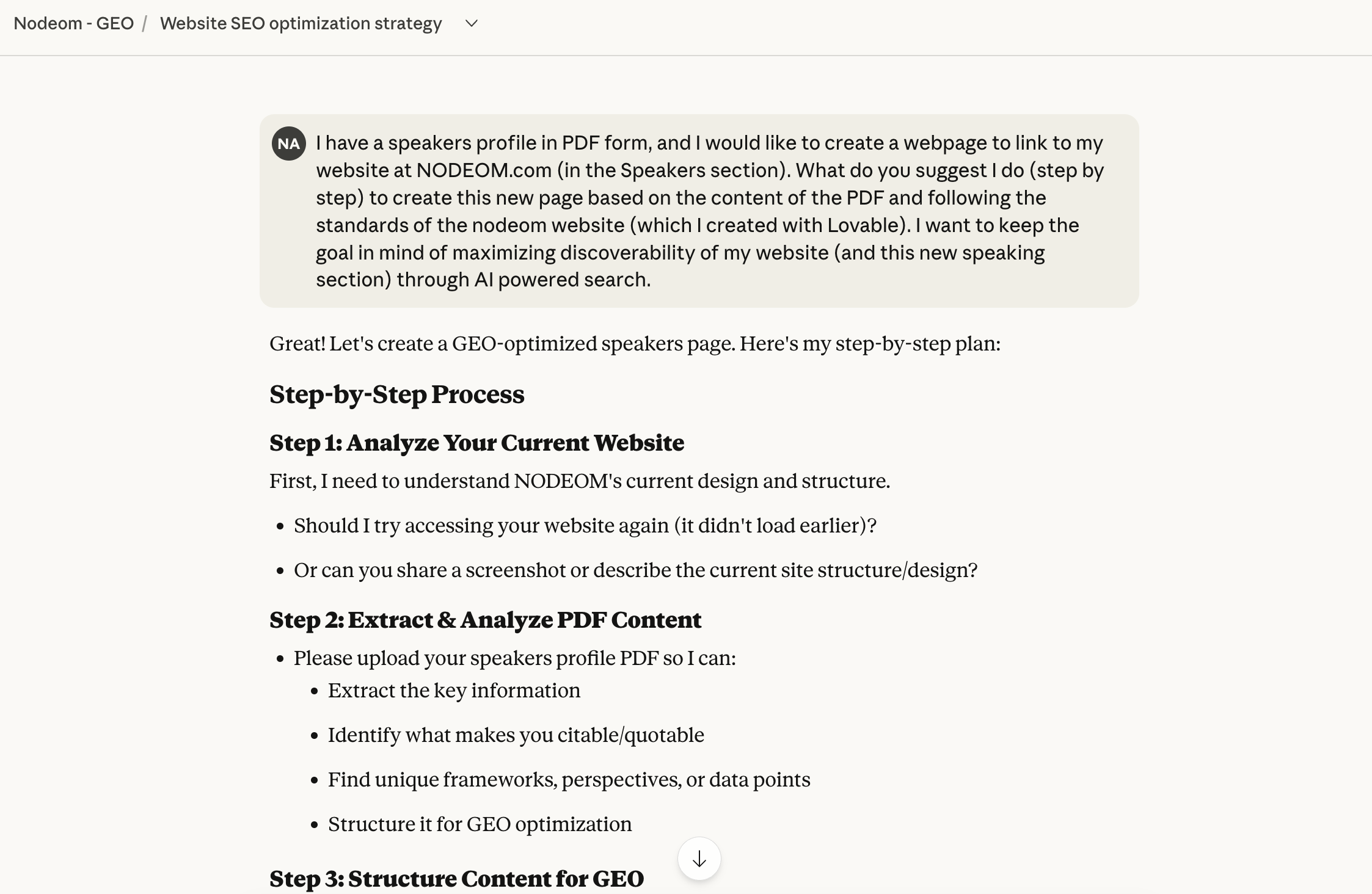
Then, Claude and I had some back and forth, mostly about the structure of the new page, adding a new section, reorganizing some FAQ sections Claude argued were better for discoverability, adding some buttons... You get the idea.
I am trying not to make my essays too long (way harder than it may appear!), so I will not bore you with the details. But if you are curious, you can read more about the process I followed below, after the essay.
After a few interactions, once I had the optimum prompt, I used it in my old Lovable project for the site, saw the preview, perused through the text, and everything looked good, so I published it.
It was only later, when I was showing the site to my husband after dinner, that I realized…
The content of my keynotes was NOT at all what I had in the PDF I provided with my instructions, which was supposed to be the source for the website!
Somewhere between Claude and Lovable, a whole new set of conferences had materialized (check the details at the end if you are curious about who’s the culprit). The new copy had something to do with what I usually talk about; it made sense, but it was… How do I say it?… Bland.
To give you an idea, the title of my first conference as it appeared in this loose version of the website was “AI Leadership and Transformation”, while the title in the original speaker profile was “Stop Dancing with AI Shadows: The Leadership Crisis We Should be Talking About”.
My first thought:
Wow! How can I have missed that? I reviewed the page several times and, although I was focusing in the functionality, I did see the text! How is that possible? Am I losing it?
Well, if 83% of radiologists could miss a gorilla 48 times larger than the average nodule3, I should not be too hard on myself. This is a clear case of inattentional blindness. I reviewed the content several times, yes, but I simply did not see what I did not expect to see.
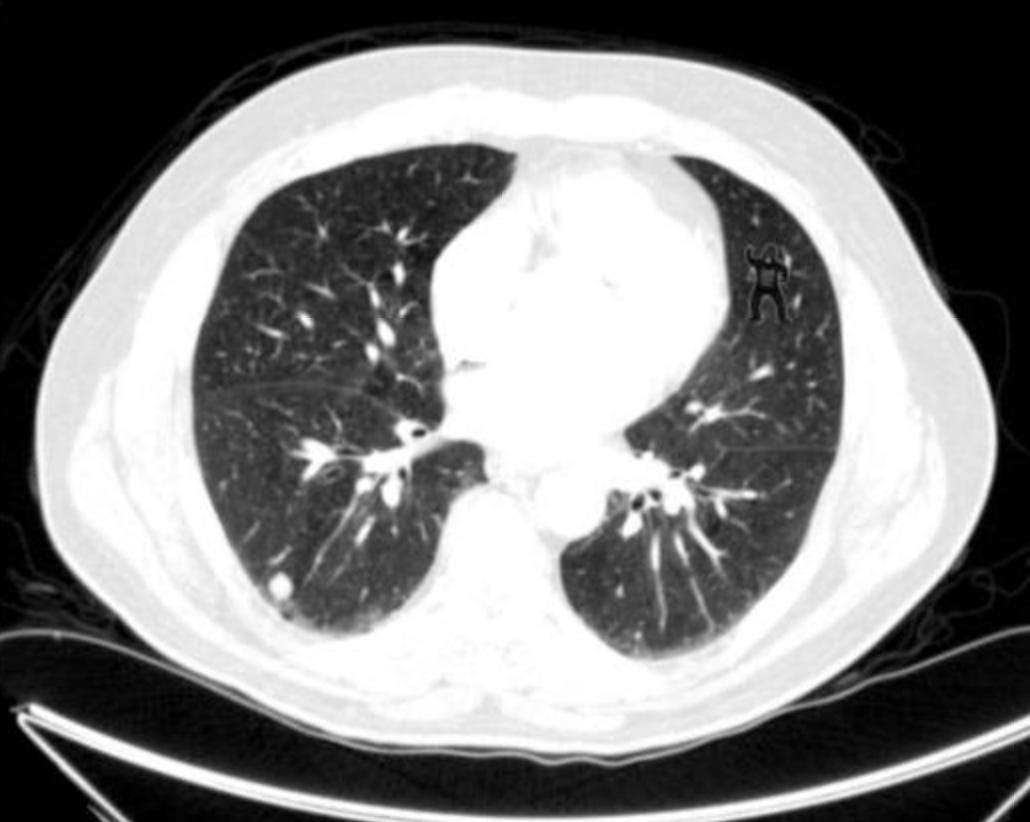
The content did not look obviously wrong upon perusal, and I knew the tools I was using could now properly extract content from PDFs, so I guess my brain simply did not expect the text change, and it did not process it.
My second thought:
I confirmed once again how important it is to create and mature my own content, no matter how hard it is, or else it could become bland and unoriginal before I know it. But I also got a creeping new doubt:
This blandness could not possibly be what’s required for my site to be more discoverable by AI-powered search, could it?
Ay ay ay! I can physically feel the downward spiral! Let me just focus on correcting that section and move on.
And so I did, after dinner, by going to Claude and asking it to change the TypeScript file that included the code for my speaker page. I also copied and pasted the text this time, to avoid any potential problems with the PDF.
Funny! In the paragraph above, I finally succeeded at writing “it” instead of “him” when referring to Claude. And Grammarly - another AI-based software that provides suggestions for better writing - marks this as an error and underlines it in red! The anthropomorphization is almost forced on me! Oh well, Claude is a man’s name after all…

Done!
Or so I thought.
The following morning, when I checked the site again upon waking up - I can be a little obsessive, I know, and it pays off sometimes - I noticed that a lot of the content in the other sections was not quite what I had in my PDF either.
Including the surprising fact that I speak Catalan, instead of Galician (Whaaaaaaat?)
So, this time, just a tiny bit frustrated (to put it mildly), I went directly into the code of the speaker page and updated the content myself.
And there came my third thought:
I really don’t need Lovable anymore. I can do everything with Claude or Claude Code. I try to diversify as much as possible the tools I use, but I can clearly feel the pull to focusing on just one, which lately is Claude. I should probably get better at resisting it, but it is difficult, and it makes me wonder about the future competitive landscape for these companies…
So, what is my conclusion after the process?
The current vibe coding tools have given me a website I fully own and can update whenever I want, without paying a subscription for tools like WordPress or Wix, while providing more freedom (I don’t have to stick to a template). And they brought me closer to the code, not further away from it, partially answering the question I asked myself in that first essay about vibe coding. It is not only because of my curiosity. After a point, it is just faster (and cheaper) to get into the code directly than to ask the tool to make changes, only to have to check whether it has done what you’ve asked.
Curious people can get a lot out of these tools for prototypes and basic applications, no question!
But I reiterate: for prototypes and basic applications. Even the father of the term vibe coding admitted that, when it came to his own open-source model, he wrote the whole thing by hand4.
I can’t help but wonder: Are these conversational interfaces the best way to extract value from the technology that exists today?
I know it’s what we’ve come to expect in the last three years, but on the one hand, the options for what you can say and how it can be interpreted are endless… And, on the other hand, how much do we miss in the review, if we can review, and if we do review?
I understand these interfaces make things immediately easier for users (at least those inexperienced at writing code like me), but then the complication shifts to the backend, doesn’t it? (Tesler already came up with his Law back the mid 80s5).
Couldn’t more innovation be driven by enabling constraints, as we’ve learned from complex systems? Just like music can be an enabling constraint for dancing, and without it we may get a bunch of incoherent movements instead of a beautiful dance, maybe we need some boundaries when accessing these technologies, or else we end up with a bunch of apps made of spaghetti code completely disconnected from each other.
The actual process, in detail, for the most curious ones
I originally made my site with Lovable, but when I thought about updating it, the little genie on my left shoulder reminded me that the last time I had made a slight update on Lovable (I think it was adding my Privacy Policy, which I also wrote about here), it broke some links on the menu. Also, I am paying for Claude Pro (the only subscription I pay for the moment), so I decided to use Claude and Claude Code (I also buy credits as needed for some recurring scripts) as much as possible instead of doing much on Lovable, for which I keep only the free version.
So, my first question was for Claude to give me the most optimized prompt I could use for my goal, considering that I was providing all of the content already in a PDF attached. There was some back-and-forth until we got to a prompt that I thought included all my requirements.

And then, I simply pasted the optimized prompt we had reached after the back-and-forth into Lovable. Please note this particular section of the prompt, where the attached document was my speaker profile in PDF.

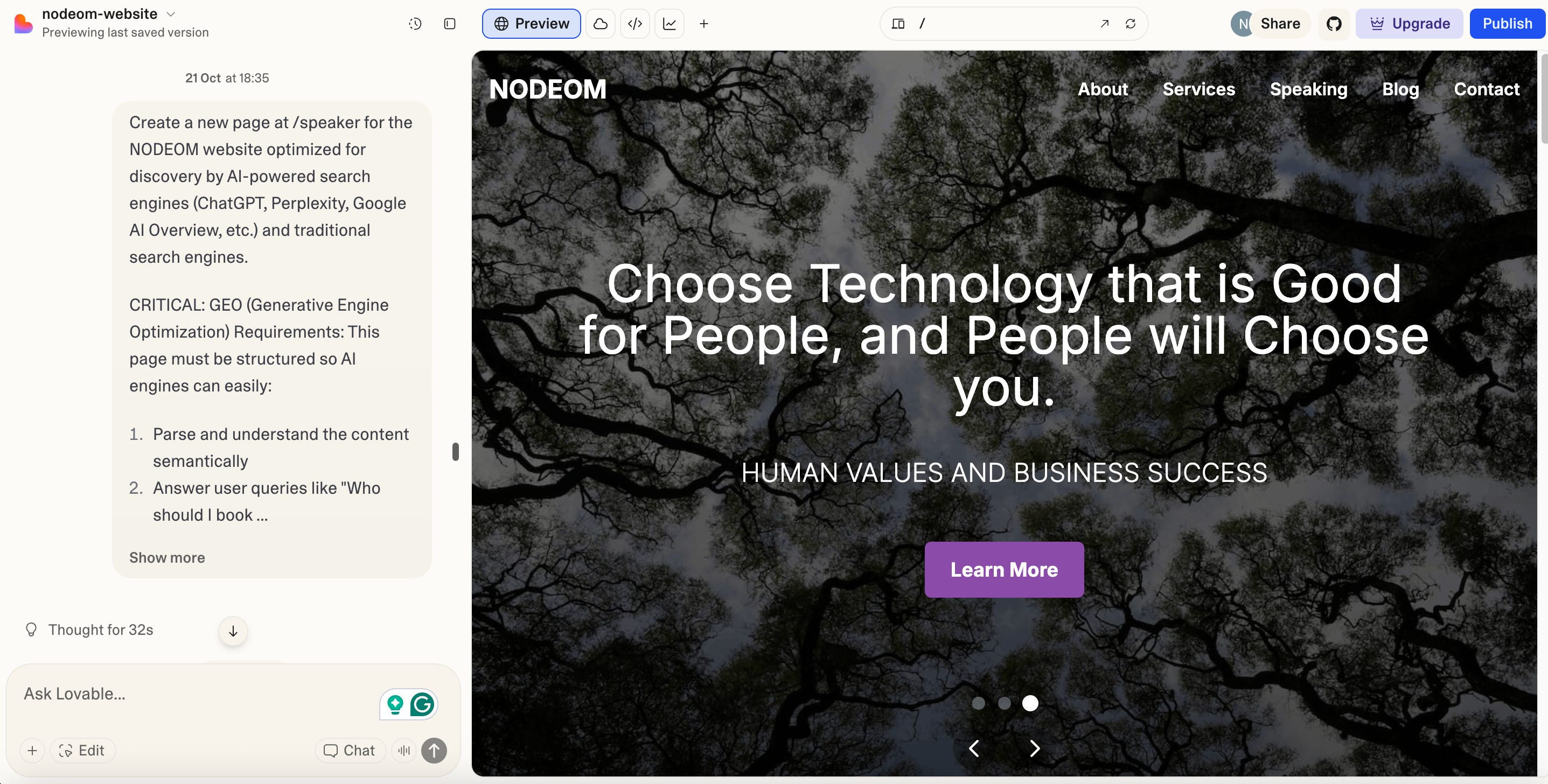
Once the page was created, it looked good enough for me to fetch it to my computer via the Github app, run the build from the Terminal app to convert the code in the project to the executable code that can run in the browser, and upload the latter to GoDaddy.
Then I focused on fixing navigation issues directly with Claude, which could either give me instructions for what to change in the code or give me files with the corrections already made. I modified or replaced the files without going back to Lovable, and I did not realize any issues with the content until the very end.
As I revisited the process to write this essay, I thought about what went wrong. Was my prompt “create this new page based on the content of the PDF” too generic? When I asked Claude, it seemed to agree:

I should have been more specific about “extracting the exact content of the PDF and using it for the page”.
How many conversations have I had with developers in my team that went down a convoluted path because of a similar “lack of specificity”? I should have learned!
There is clearly no issue with the technical capability of extracting the text from a PDF, and it does that perfectly when you specifically ask, as I double-checked with Claude:
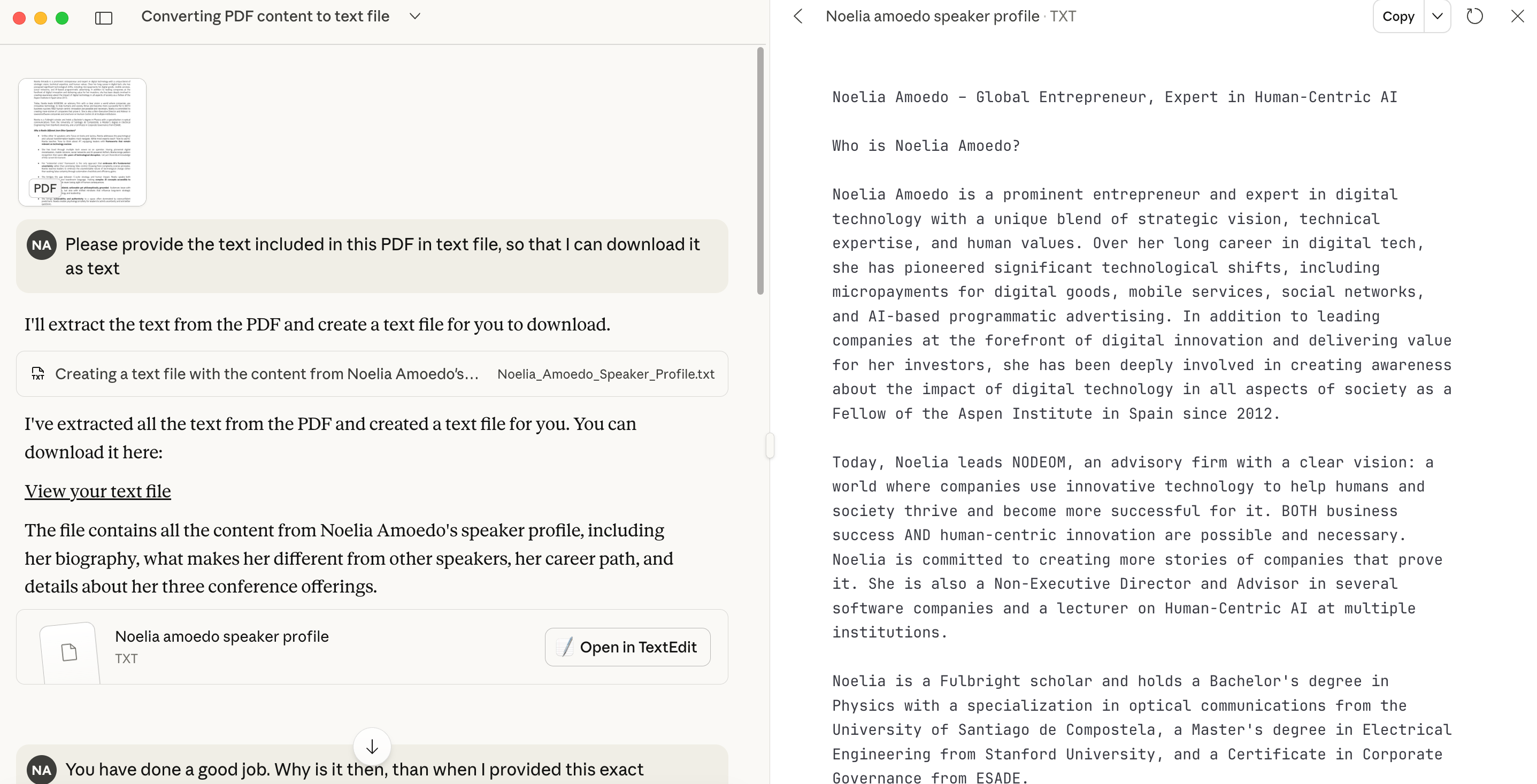
So, the instructions were just not clear enough, I almost concluded.
As you may have guessed, I also tend to start with myself when things don’t go well. “What could I have done differently?” is often the first question that comes to mind.
But then, I realized that it was not Claude who created the first version of the code including the text, but Lovable! And, although Lovable used to be based on the same models as Claude a few months ago, the app seems to be using Gemini models by default now, and Open AI in some cases (https://docs.lovable.dev/features/ai). The prompt included the clear instruction to “use the exact copy of the PDF” and it was simply ignored by Lovable.
Did it have an issue extracting the text, and it did not made that clear to me? Did it have conflicting priorities and changed the content for better discoverability, again, without telling me?
I do not know.
Whatever the case, more transparency by default around the deviations from the PDF would have been great (as it was a clear instruction).
And, yes, I could have paid more attention.
Giving into the vibes: https://x.com/karpathy/status/1886192184808149383?lang=en
AI search engines analyze the context, intent, and semantics of queries instead of using keyword-based indexing like traditional search engines. Examples are Google Overview (showing up on top above traditional search results in many queries), chatGPT search or Perplexity. Basically, when you ask an AI chatbot to find information from the web, you are using AI-powered search.
An experiment in 2014 asked 24 radiologists to perform a familiar lung nodule detection task. A gorilla, 48 times larger than the average nodule, was inserted in the last case. 83% of radiologists did not see the gorilla. Eye-tracking revealed that the majority of those who missed the gorilla looked directly at the location of the gorilla. Even expert searchers, operating in their domain of expertise, are vulnerable to inattentional blindness. Full study here: https://pmc.ncbi.nlm.nih.gov/articles/PMC3964612/#:~:text=83%25
Back to writing code by hand when it matters: https://archive.is/WfLJy
Tesler’s Law: https://en.wikipedia.org/wiki/Law_of_conservation_of_complexity. The complexity in a system does not disappear. It only shifts. Tesler established this in the context of UX: when an interface becomes simpler, the complexity is being shifted to the backend.